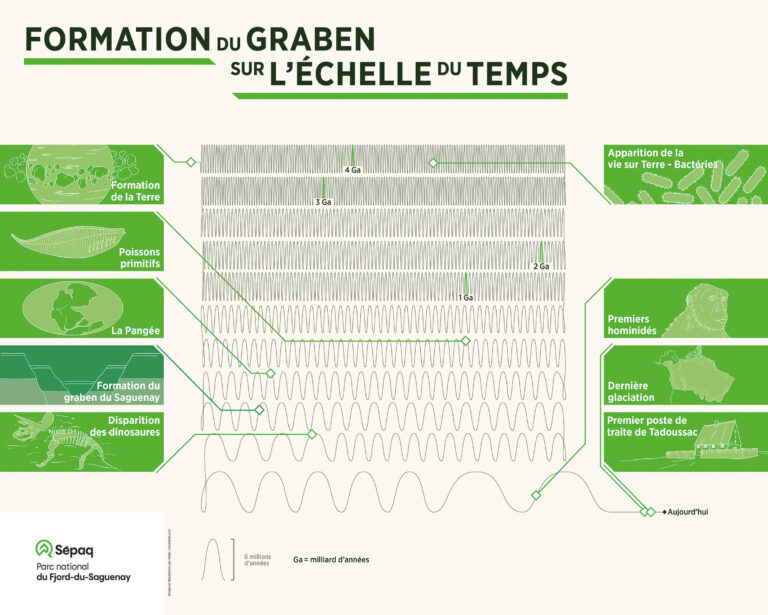
Most of the time, the choice of scale is based on the data. Sometimes, however, the exercise is more complicated, as it was the case when the Société de établissements de plein air…
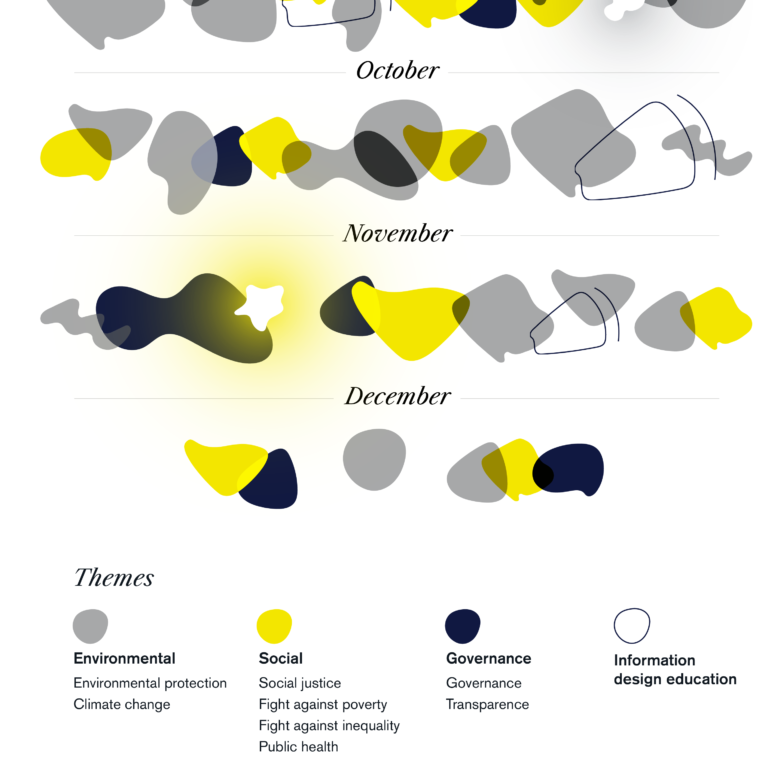
This month, I visited the Emerging Patterns exhibition at the Thomas Fisher Rare Book Library in Toronto, where curators Aurora Mendelsohn, Anthony Gray and…
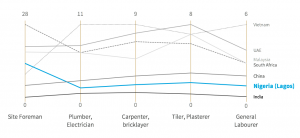
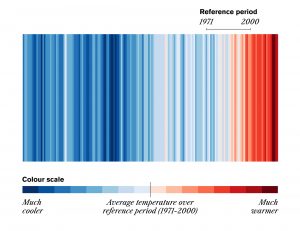
In dataviz, we often deal with numbered abstractions. But when the Canadian Climate Institute came to us with research about infrastructure, a topic connected…